집순 프로젝트 후기
1. 부동산은 불편하다
-
저는 네이버 부동산으로 남의 집을 염탐하는 것을 좋아합니다. “저기서는 어떻게 살아볼까” 새로운 삶을 꿈꿔보곤 해요.
-
그런데 그거 아시나요. 내 기호에 딱 맞는 부동산을 찾아주는 서비스는 어디에도 없습니다.
-
네이버 부동산이나 직방, 피터팬 뿐만이 아닙니다. 북미의 zillow, realtor 등도 마찬가지입니다.
-
다들 이렇게 말하는 듯합니다. “네가 뭘 원하는 지는 모르겠어, 여기 다 줄테니 알아서 체크박스에 클릭해. 방 2개, 에어컨 1개, 욕조 1개.”
-
하지만 이것만으론 부족합니다.
-
누군가는 편의점이 가깝기를, 누군가는 체육시설이 주변에 있기를 바랄 수도 있죠. 누군가는 지하철만 좋아하고 버스는 싫어하지만, 누군가에겐 둘 다 상관 없을 수도 있습니다. 주차장에 물이 잠기는게 무서워 지형상 고지대를 선호할수도 있구요. 상대적으로 제일 낮은 범죄율의 도시에 살고싶어할 수도 있습니다.
집순 프로젝트가 만들어진 이유입니다.
다양한 부동산 정보를 조합해 의사 결정을 돕고 싶다.
2. 컨셉
-
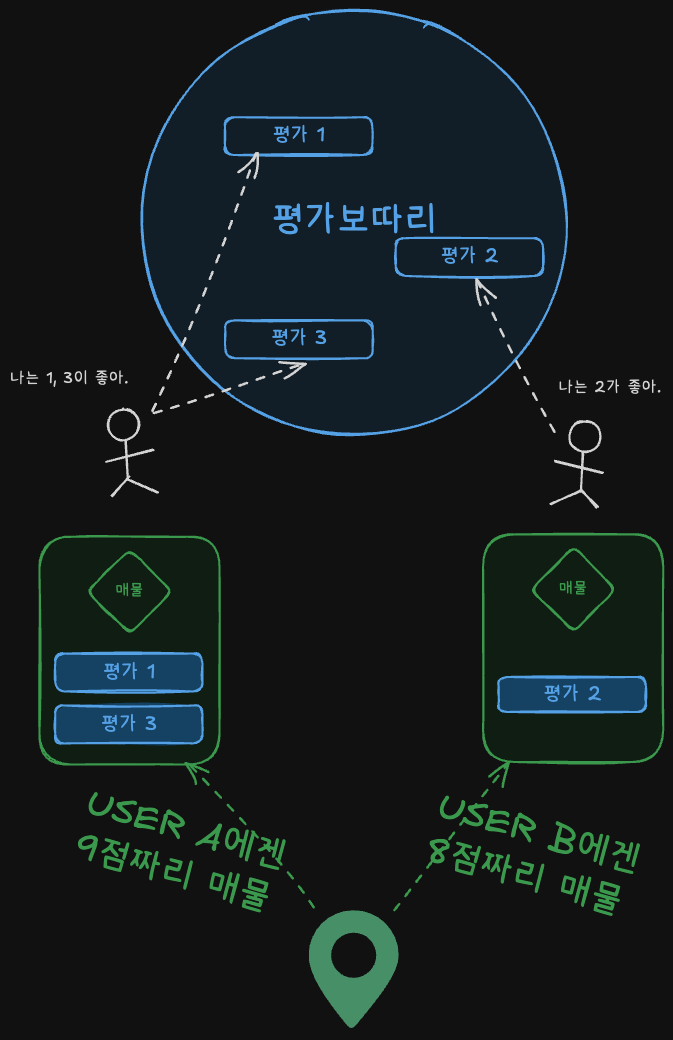
유저마다 개인화된 매물 점수를 제공하고 싶었습니다.
-
유저에게 여러 가지 평가 방식을 제시한 뒤,
-
유저가 스스로 평가 방식을 조합해 나만의 매물 점수를 가지게 하고 싶었습니다.
-
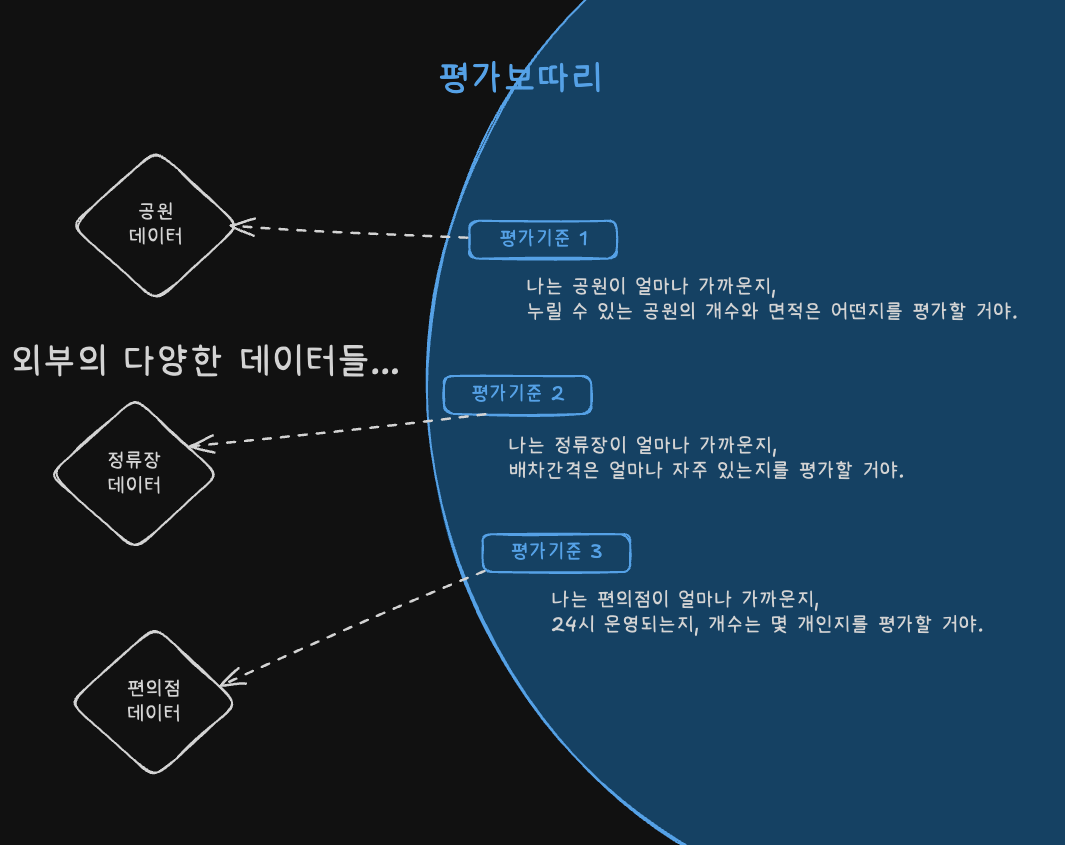
그런데 잘 생각해보면, 평가를 하기 위해서는 데이터가 필요합니다.
-
가령 매물의 공원 접근성을 평가하려면, 적어도 전국에 있는 공원의 위치나 면적 등은 가지고 있어야 하죠.
-
그래서 각 평가의 원천 정보를 수집하고 적재하는 파이프라인도 만들기로 했습니다.
3. 구현
➊ 매물 수집 → ➋ 매물 점수 계산에 필요한 정보 수집 → ➌ 매물 점수 계산 → ➍ 정규화
-
집순의 데이터 처리 과정은 네 단계로 구성됩니다.
-
각 단계는 Job으로 구성돼 있습니다. DataPipelineService가 job을 순서대로 실행합니다.
-
각 단계는 수평적 확장에 열려있습니다.
- 가령 ➌ 매물 점수 계산 컴포넌트를 새로 만들고 싶다면, ScoreCalculator 인터페이스를 따르는 새 클래스를 만들어 추가하면 됩니다.
➊ EstateJob
부동산 매물을 찾아 DB에 저장합니다. 이를테면 네이버 부동산에서 네이버 매물을 json으로 가져오는 식이죠.
➋ SourceJob
매물 점수 산정에 필요한 데이터를 DB에 저장합니다. 이를테면 전국 공원 정보가 담긴 csv 파일을 테이블에 저장하는 식이죠.
➌ ScoreJob
특정 척도에 따라 매물별로 점수를 계산합니다. 이를테면 공원의 개수, 면적 등을 고려해 11, 20, 19 따위의 점수를 내는 식이죠.
➍ NormalizeJob
계산된 점수를 0-10점 사이로 정규화합니다. 이를테면 11, 20, 19 따위의 점수를 5, 10, 7점 따위로 변환하는 식이죠.
4. 운영환경 가정하기
- 일부 챌린지는 요청을 얼마나 효율적으로 처리하는지를 다룹니다.
- 그러므로 집순 서비스의 운영환경을 가정하고, 부하를 추정해 보겠습니다.
초당 요청 수(RPS)
- RPS는 서버의 처리 성능을 나타내는 지표입니다. 1초에 얼마나 많은 요청을 처리하는지를 나타냅니다. RPS = \frac{Total\ Requests}{Total\ Time\ (seconds)}
피크타임 초당 요청 수(RPS peak)
-
저는 높은 부하가 걸리는 시간대의 RPS를 추정하고자 했습니다. 다음과 같이 계산해 보겠습니다1. RPS_{peak} = \frac{Peak\ Requests}{Peak\ Time\ (seconds)} = \frac{DAU \times RPU \times r_{peak}}{t_{peak}}
- DAU: 일 사용자 수
- RPU: 1인당 평균 요청 수
- r_peak: 피크 시간대 요청 비율 (총 요청 중 피크에 발생하는 요청의 비율)
- t_peak: 피크 시간대 길이
-
이제 각 요소를 추정해 보겠습니다.
결론
RPS_{peak} = \frac{100,000 \times 30 \times 0.1}{7,200} = \frac{300,000}{7,200} \approx 41.67
- 집순은 최대 초당 약 42개의 요청을 처리할 수 있어야 합니다.
- 여유롭게 설계하기 위해 목표 RPS는 50으로 설정하겠습니다.
5. 챌린지: 공간 쿼리 도입하기
문제
-
부동산 매물은 위치 기반 검색이 필수적입니다.
-
일반적인 좌표 기반 쿼리(
WHERE X >= ? AND X <= ? AND Y >= ? AND Y <= ?)는 데이터가 증가할수록 성능 저하를 겪을 수 있습니다. -
최대 부하 상황(50명의 동시 접속자)에서도 안정적인 성능을 제공해야 합니다.
해결
-
PostGIS의 공간 인덱스를 도입했습니다.
-
위치 정보를 효과적으로 처리하기 위해 Geometry 객체를 사용하고, 그에 맞는 TypeHandler를 구현했습니다.
성과
-
다양한 데이터를 대상으로 성능 및 부하 테스트를 거쳤습니다.
-
부하(피크) 상황에서, PostGIS와 일반 쿼리의 응답 시간을 비교했습니다5.
-
속도: PostGIS는 일반 쿼리보다 5배 빠른 응답 시간을 제공합니다6.
-
안정성: PostGIS는 응답 시간의 변동성을 낮춰 일관된 사용자 경험을 제공합니다.
-
확장성: 전국 단위로 확장하더라도, 부하 상황에 흔들리지 않는 서비스를 제공할 수 있습니다7.
한계
-
부하 상황이 균등하게 주어진다고 가정했기 때문에, 초당 50개 이상의 요청이 발생할 경우를 생각해 봐야 합니다.
-
테스트에 testcontainers를 사용했기 때문에, 실제 운영 환경과는 차이가 있을 수 있습니다. 실제 환경에서는 여러 독립적 구성 요소(CPU, 디스크 I/O, 네트워크 등) 지연 시간이 곱으로 누적됩니다.
6. 챌린지: 요청 추적 도입하기
문제
-
로그 크기가 늘어날수록 텍스트 기반 검색은 선형적으로 느려집니다.
-
서비스가 확장되며 분리된다면, 사용자 요청과 로그가 분산되기에 문제 추적이 어려워집니다.
해결
-
요청 추적을 위해 RequestID 필터를 구현했습니다.
-
모든 요청에 UUID 기반의 RequestID를 발급하여 MDC에 저장하고, 응답 헤더에도 포함합니다.
성과
-
속도: Request ID 기반 검색은 아주 빠르며(0.07ms), 일반 텍스트 검색 대비 1530.12ms(약 1.5초) 더 빠릅니다.
-
확장성: 로그가 지수적으로 증가하더라도 동일한 검색 속도를 유지하며, requestId 기반의 모니터링 툴을 연동할 수도 있습니다.
한계
-
더 적은 로그 수에서는 검색 속도 개선이 의미가 없을 수 있습니다.
-
실제 운영 환경에서는 테스트 환경보다 더 복잡한 로그 패턴과 구조가 발생할 수 있습니다.
-
분산 시스템에서의 지원은 미비합니다. Datadog, ELK 스택 등과 통합하면 더 효율적으로 운영할 수 있습니다.
7. 후기
배경
-
저는 공간과 도시에 관심이 많습니다.
-
어릴 때부터 시뮬레이션, 특히 도시 건설 게임을 즐겨 하곤 했지요. 도시 건설 게임들은 현실을 멋드러지게 모방해 깔끔하게 보여줍니다.
게임 심시티 4의 화면입니다. 집값, 교통 등을 보기 쉽게 표현해 플레이어가 도시 어느 곳을 어떻게 손봐야 할 지 인사이트를 제공합니다.
출처: Simtropolis forum, #1 #2
원하던 것
-
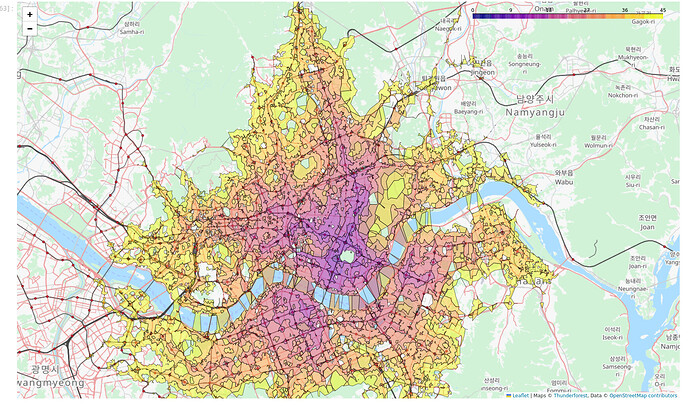
사실 제가 진짜 만들고 싶었던 서비스는 등시선도를 보여주는 어플리케이션이었습니다.
-
예컨대 다음 그림에서처럼, 성수에서 대중교통을 타고 45분 이내에 도착할 수 있는 모든 지점을 시각화 하는 거죠.
특정 지점으로부터의 거리나 시간 등을 보여주는 방사형 지도를 등시선도isochrones라고 합니다.
출처: Graphhopper forum, South Korean public transit isochrones
-
즉 집을 찾을 때마다 제가 일일이 눌러보는 수고를 덜어줄 일종의 GIS가 필요했던 셈입니다.
-
지도에 색이 칠해져 있다면 제가 원하는 지역, 제가 원하는 집을 한눈에 볼 수 있을 테니까요.
-
그래서 프로젝트 초반에는 라우팅 엔진(길 찾는 엔진)을 조사하고 MVP를 만드느라 시간을 좀 허비했습니다.
-
결과적으로 적절한 라우팅 엔진을 찾았고, OpenStreetMap에 등시선도를 간단히 그려 보았습니다만,
-
상용 서비스로 내세우기엔 추가 실험과 튜닝이 필요한 부분이 많았습니다.
현실
-
결국 저는 등시선도를 서브 기능으로 추가할 수 있는 매물 평가 서비스로 선회하게 되었습니다.
-
매물 평가를 컴포넌트화해 추가 확장 개발의 여지를 열어 두면서도, 당장 더 쉬운 목표를 완성하기 위해서였죠.
결과
-
많은 부분을 돌고 타협했지만
-
batch, security, aop도 써 보고
-
공간 쿼리도 경험해 보고
-
다양한 테스트 코드도 작성해 보고
-
무엇보다 제가 늘 원하던 앱을 만들 수 있었다는 점에
-
-
만족스러운 프로젝트였습니다.
-
확실히 제가 재밌어하는 부분을 만드니, 시간 가는 줄(=돈 새는 줄)도 모르고 열심히 하게 되더군요.
-
당장은 취업과 포트폴리오가 급해 폴리싱을 마치고 손을 더 대지 않았지만,
-
심적(=돈적) 여유가 생기면 실제 사용자를 받는 제 첫 웹서비스가 되길 손꼽아 기다리고 있습니다.
개인적인 글 시간 내어 찬찬히 읽어주셔서 감사합니다.
References
-
피크 요청이 평균 요청보다 얼마나 높은지 비율을 알 수 있다면, 피크 요청 수를 구할 수 있습니다.피크\ 요청\ 수 = ➊전체\ 요청\ 수 \times ➋총\ 요청\ 중\ 피크에\ 발생하는\ 요청의\ 비율➊은 DAU(일일 사용자 수)와 RPU(일인당 평균 요청 수)를 활용합니다. 다른 기업의 지표를 참고하기 쉬워서입니다. 전체 요청 수 = DAU * RPU입니다. ➋는 단순 휴리스틱으로 정했습니다. 후술하겠지만 서비스별 피크 요청의 비율을 일반화하기 어렵기 때문입니다. ↩
-
호갱노노, 직방의 2020년 안드로이드 DAU는 각각 30만, 25만입니다. 2024년 총 DAU는 각각 53만, 34만입니다. 이에 근거해 직방의 DAU를 30만 정도로 추산했습니다. ↩
-
집순의 엔드포인트 수와 유즈케이스를 고려했습니다.
카테고리 엔드포인트 요청 횟수/세션 매물 관련 GET /estates/map (지도 로딩 및 이동) 10-15회 GET /estates/{id} (매물 상세 조회) 5-8회 POST /estates/{id}/favorite (찜하기) 1-2회 DELETE /estates/{id}/favorite (찜 해제) 1-2회 점수 유형 GET /score-types (점수 유형 조회) 1-2회 POST/DELETE /score-types/{id} (활성/비활성) 1-2회 사용자 GET /users/me/favorites (찜 목록 조회) 1-2회 총 요청 수/세션 20-30회 -
프롭테크 서비스의 시간-요일-계절별 트래픽 패턴은 알려진 바가 없습니다. 다만 이커머스의 경우, 시간대별 구매 패턴이 잘 알려져 있습니다. 한 조사에 따르면 오전 10시와 12시에 가장 많은 구매가 일어납니다.
시간대 구매 수 퍼센트(%) ... ... ... 10:00 56개 6.67% 11:00 53개 6.32% 12:00 56개 6.67% ... ... ... 이 구매 트래픽을 조회 트래픽으로 단순 변환했습니다. 어떤 서비스들은 피크 시간대에 20-30%의 부하를 겪는다고 조사했으나, 근거가 명확치 않아 제외합니다. ↩ ↩2
-
테스트는 최대 ➊150만개의 레코드 테이블에 ➋200번의 요청을 10번 보내는 것으로 진행합니다. ➊의 값은 2023년 기준 대한민국의 총 건물 수에서 추정했습니다. ➋의 값은 여러 번의 실험을 통해 추정했습니다.
표본이 모집단을 대표하려면 충분한 샘플 수가 필요합니다. 여기서의 샘플 수 = 부하 테스트 요청 수입니다. 안타깝게도 백분위수 추정에 필요한 샘플 수를 정확히 구하는 것은 깊은 통계학적 지식을 요구합니다. 그래서 대략적인 필요치만을 조사한 뒤(15,000~17,000), 변수들을 조금씩 조정하며 관찰하는 방법을 택했습니다.총\ 표본\ 수\ n=50 \times T_p \times k \times B50은 초당 요청 수, Tp는 부하 시간 초, k는 재시행 횟수, B는 부트스트랩 횟수입니다. 즉 50Tp만큼 요청하는 부하 테스트를 k번 반복한 뒤, B만큼 재추출하겠다는 뜻입니다. 여기서 (Tp, k, B)를 조정하며 실험 결과를 관찰했고, 최종 값은 (4, 10, 1000)으로 정했습니다. ↩
-
부하 상황에서 사용자가 겪는 지연 환경을 재현하기 위해 P95값을 추정했습니다. 계산 결과 ➊PostGIS는 418.9ms, ➋일반 쿼리는 2148.7ms입니다.
이는 피크타임에서 ➊PostGIS 사용자들의 95%는 418.9ms보다 낮은 지연시간을, ➋일반 쿼리 사용자들의 95%는 2148.7ms보다 낮은 지연시간을 경험할 것이라는 뜻입니다.
-
Jakob Nielsen의 UI/UX 응답 시간 가이드라인에 따르면, 반응 속도가 0.1초는 즉각적, 1초는 방해받지 않는 수준, 10초는 인내심의 마지막 단계라고 설명합니다. 부하 상황에서 데이터베이스 레벨의 416.88ms 지연은 “방해받지 않는 수준”이라고 해석할 수 있습니다. ↩
-
3,000만줄은 1일 추정치입니다. 앞서 DAU를 10만명, RPU를 30회/일로 가정했으므로 일\ 평균\ 총\ API\ 요청\ 수 \approx 10만명 \times 30회 = 300만\ 요청/일 각 요청이 평균 10줄의 로그를 생산한다고 가정하면 일\ 평균\ 로그\ 수 = 300만\ 요청/일 \times 10줄 = 3,000만줄 각 요청에서 생성되는 로그의 양은 다음과 같이 가정했습니다.
카테고리 로그 유형 발생량/API 요청 API 요청당 평균 로그 API 입출력 로그 2개 서비스 레이어 로그 3-5개 데이터베이스 조회 로그 2-3개 총 로그 발생량/API 요청 7개-10개